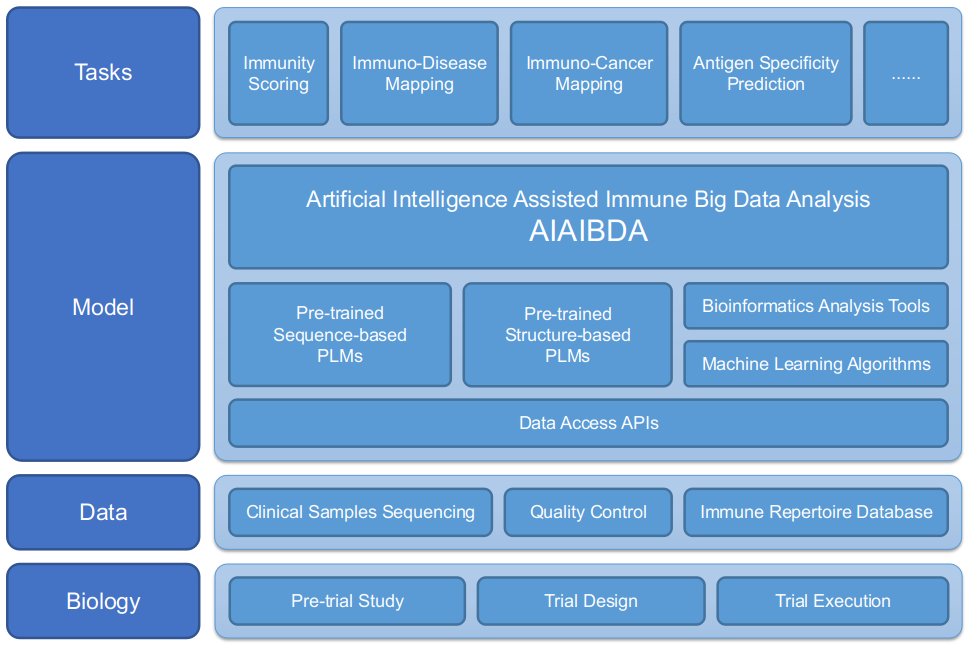
中国癌症发病率高
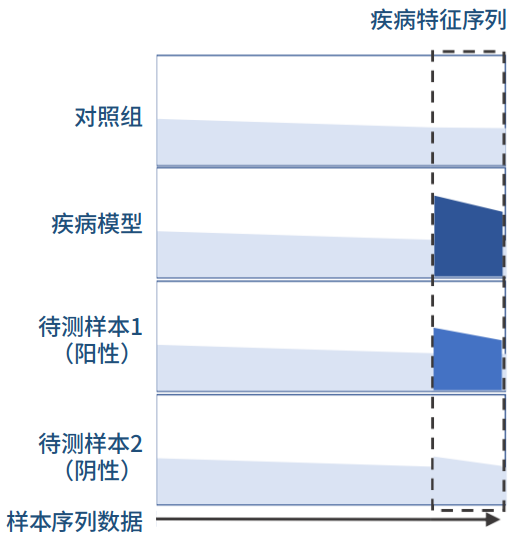
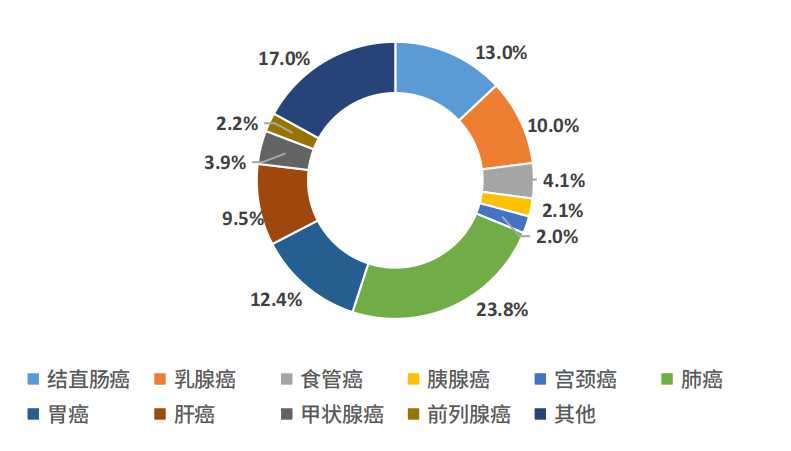
根据世界卫生组织癌症研究机构(IARC)发布的《2020年世界癌症报告》,2020年中国新发癌症457万例,死亡300万例,分别占全球新发与死亡病例的23.7%和30.2%,位居全球第一,且近十年来癌症发病率和死亡率均呈持续上升趋势。
图1. 2020年中国癌症新发人数占比
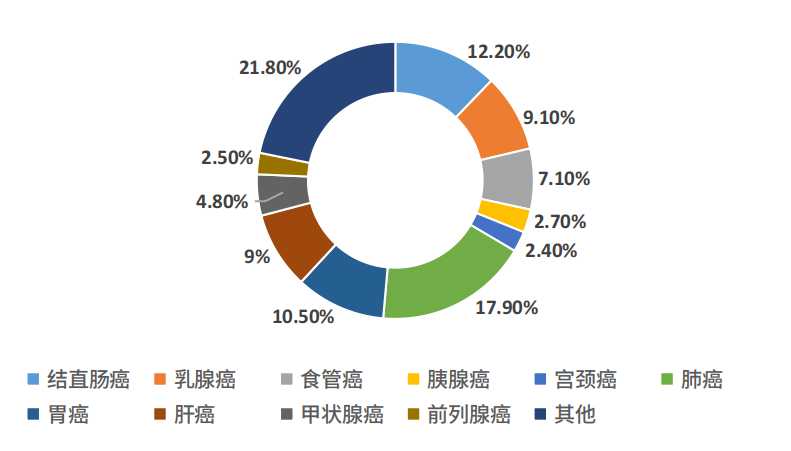
图2. 2020年中国癌症死亡人数占比
中国癌症早诊断率低
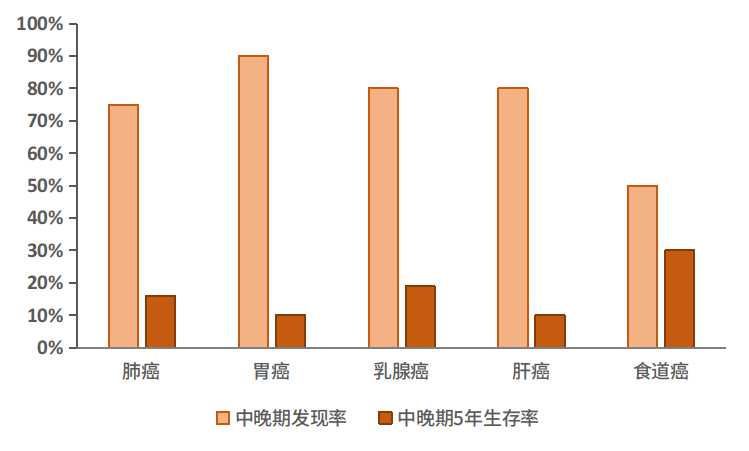
根据世界卫生组织数据,1/3的癌症可以通过早期诊断而得到治疗。肿瘤早期体积小,未发生转移,较容易切除,早期癌症的治愈率可高达90%。然而,中国目前新发癌症患者80%以上属于中晚期,所有癌症的五年生存率仅为40.5%,远低于美国的67.1%。
图3. 中国癌症早期发现率和5年生存率
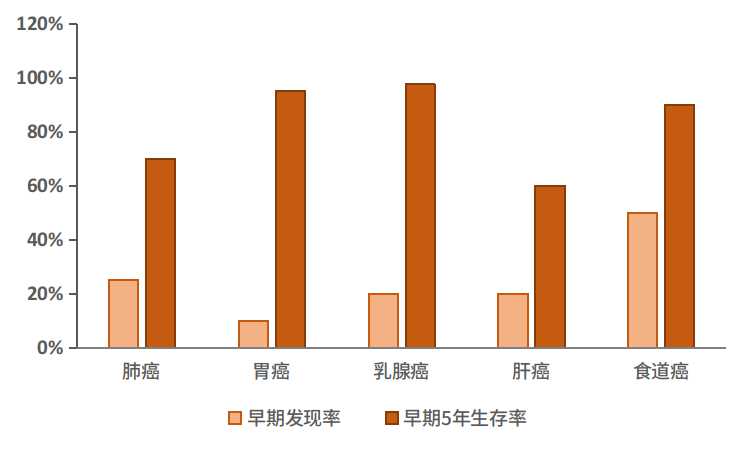
图4. 中国癌症中晚期发现率和5年生存期
癌症的早期筛查能有效降低患病率,并提高患者生存率。以结直肠癌为例,根据《2020 年中国结直肠癌筛查与早诊早治指南》,结直肠癌的发生发展大多遵循“腺瘤-癌”序列,从癌前病变进展到癌一般需要 5-10 年时间,为疾病的早期诊断和临床干预提供了宝贵时间窗口。此外结直肠癌的预后与诊断分期紧密相关,I 期结直肠癌的 5 年相对生存率超90%,而发生远期转移的 IV 期结直肠癌 5 年相对生存率在 15%以下。对于其他癌种,早期筛查与诊断同样有利于即早干预治疗,提升患者生存率。
因此,癌症早查早治,对提高生存率及生存质量,意义重大;推广普及癌症早期筛查,很有必要!